在探索手游AI与数据处理的奇妙世界时,我们时常会遇到一个挑战:如何为模型同时输入不同维度的数据?这对于追求极致游戏体验的玩家和开发者来说,无疑是一个值得深入探讨的话题,就让我们以PyTorch为武器,一起揭开这个神秘的面纱,看看如何在手游开发中玩转多维数据输入!
在手游开发中,我们经常需要处理来自不同来源的数据,比如图像、文本、传感器信息等,这些数据往往具有不同的维度和格式,如何有效地将它们整合到模型中,是提升游戏智能和体验的关键,PyTorch,作为深度学习领域的佼佼者,为我们提供了强大的工具和方法,让我们能够轻松应对这一挑战。
想象一下,你正在开发一款结合了图像识别和自然语言处理的手游,玩家在游戏中需要识别并理解图像中的物体,同时输入文本指令进行交互,这时,你的模型就需要同时处理图像数据和文本数据,而这两者的维度显然是不同的,图像数据通常是三维的(高度、宽度、颜色通道),而文本数据则是一维的(词向量序列)。
如何在PyTorch中实现这一功能呢?答案是通过自定义模型结构和数据预处理流程。
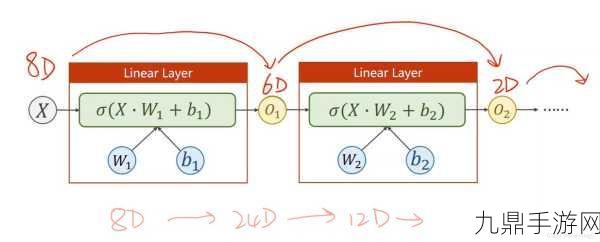
你需要定义一个能够接收不同维度输入的自定义模型,这可以通过继承torch.nn.Module类来实现,在你的模型中,你可以为不同类型的输入数据设计不同的处理层,比如卷积层(Conv2d)用于处理图像数据,线性层(Linear)用于处理文本数据,你可以使用torch.cat()函数在特征维度上将不同处理层输出的特征拼接起来,形成一个统一的特征向量,将这个特征向量送入全连接层进行进一步的处理和输出。
以下是一个简单的代码示例,展示了如何在PyTorch中实现这一过程:
import torch
import torch.nn as nn
class MultiModalModel(nn.Module):
def __init__(self):
super(MultiModalModel, self).__init__()
# 图像数据处理层
self.conv_layer = nn.Sequential(
nn.Conv2d(3, 16, 3), # 假设输入图像有3个颜色通道,使用16个卷积核,卷积核大小为3x3
nn.ReLU(),
nn.MaxPool2d(2) # 使用2x2的最大池化层
)
# 文本数据处理层
self.text_layer = nn.Sequential(
nn.Linear(300, 128), # 假设文本数据经过词嵌入后有300维,输出为128维
nn.ReLU()
)
# 拼接后的全连接层
# 假设图像经过处理后维度为(batch_size, 16*111*111),文本数据维度为(batch_size, 128)
# 则拼接后的特征维度为(batch_size, 16*111*111+128)
self.fc_layer = nn.Linear(16*111*111 + 128, 10) # 假设最终输出为10类
def forward(self, img, text):
# 处理图像
img_features = self.conv_layer(img)
img_features = img_features.view(img_features.size(0), -1) # 展平为一维向量
# 处理文本
text_features = self.text_layer(text)
# 拼接图像特征和文本特征
combined_features = torch.cat((img_features, text_features), dim=1)
# 前向传播到全连接层
output = self.fc_layer(combined_features)
return output
模型创建
model = MultiModalModel()
数据输入示例(假设batch_size为8)
img_data = torch.randn(8, 3, 224, 224) # 图像数据
text_data = torch.randn(8, 300) # 文本数据
前向传播
output = model(img_data, text_data)
print(output)在这个示例中,我们定义了一个名为MultiModalModel的自定义模型,它包含图像处理层、文本处理层和拼接后的全连接层,通过调用forward方法,我们可以同时输入图像数据和文本数据,并得到模型的输出。
在实际应用中,你可能需要根据具体问题的复杂程度对模型结构进行调整和优化,你可以使用更复杂的卷积神经网络(CNN)来处理图像数据,使用循环神经网络(RNN)或Transformer来处理文本数据,甚至引入注意力机制来增强模型对不同输入数据的理解和融合能力。
让我们来看看几个与PyTorch多维数据输入相关的最新手游热点或攻略互动吧!
热点一:图像识别+文本指令的冒险游戏
在这款游戏中,玩家需要识别游戏中的图像元素(如怪物、道具等),并通过输入文本指令来进行交互,游戏使用了PyTorch构建的多模态模型来同时处理图像和文本数据,实现了精准的图像识别和流畅的文本交互体验,玩家可以通过输入“攻击XX怪物”或“拾取XX道具”等指令来操控游戏角色,享受前所未有的冒险乐趣。
玩法提示:在游戏中,玩家可以通过点击屏幕上的图像元素来触发识别功能,并在弹出的输入框中输入文本指令,游戏会根据玩家的指令进行相应的操作,并给出实时反馈。
热点二:结合传感器数据的AR手游
这款AR手游将玩家的手机传感器数据(如加速度计、陀螺仪等)与图像数据相结合,为玩家提供了更加沉浸式的游戏体验,游戏使用了PyTorch构建的多传感器融合模型来同时处理图像和传感器数据,实现了精准的AR定位和交互功能,玩家可以通过移动手机来操控游戏角色,并在游戏中探索各种奇妙的场景和物品。
玩法提示:在游戏中,玩家可以通过移动手机来改变视角和位置,同时可以通过点击屏幕上的按钮来进行交互操作,游戏会根据玩家的移动和点击来更新场景和物品的位置和状态。
热点三:多模态输入的解谜游戏
这款解谜游戏结合了图像、文本和音频等多种输入方式,为玩家提供了更加丰富的游戏体验,游戏使用了PyTorch构建的多模态模型来同时处理这些不同维度的数据,并实现了精准的解谜逻辑和提示功能,玩家需要通过观察图像、阅读文本和听取音频来找到线索并解开谜题。
玩法提示:在游戏中,玩家可以通过点击屏幕上的不同区域来触发不同的输入方式(如观察图像、阅读文本或听取音频),游戏会根据玩家的输入来给出相应的线索和提示,帮助玩家解开谜题并通关。
这些热点游戏不仅展示了PyTorch在多维数据输入方面的强大能力,还为玩家提供了更加丰富和沉浸式的游戏体验,PyTorch在多维数据输入方面到底有哪些特别之处呢?
最新动态:
1、灵活性:PyTorch提供了灵活的模型定义和数据预处理流程,让开发者能够轻松地构建能够处理不同维度输入的多模态模型。
2、高效性:PyTorch的动态计算图和高效的GPU加速能力使得模型训练和推理过程更加快速和高效。
3、可扩展性:PyTorch拥有丰富的生态系统和活跃的社区支持,开发者可以轻松地获取最新的算法和工具来优化和扩展自己的模型。
PyTorch为手游开发者提供了强大的工具和方法来应对多维数据输入的挑战,通过自定义模型结构和数据预处理流程,我们可以轻松地实现多模态输入功能,并为玩家提供更加丰富和沉浸式的游戏体验,如果你也是一位热爱手游开发的玩家或开发者,不妨尝试一下PyTorch的多维数据输入功能吧!