在手游的世界里,数据就是我们的宝藏,无论是想了解游戏的最新动态,还是挖掘隐藏的游戏攻略,数据都扮演着至关重要的角色,而Python爬虫技术,正是我们获取这些数据的强大工具,我们就来聊聊Python爬虫中的lxml模块安装导入和xpath基本语法,看看它们如何助力我们解锁手游数据的新世界。
lxml模块的安装与导入
lxml模块是Python的一个解析库,主要用于解析HTML和XML文件,对于手游玩家来说,这意味着我们可以利用它来抓取游戏官网、论坛、社区等网站上的数据,比如游戏更新公告、玩家攻略、角色信息等。
安装lxml模块非常简单,只需打开你的命令行工具(如cmd或终端),然后输入以下命令:
pip install lxml
等待安装完成后,你就可以在你的Python代码中导入lxml模块了,我们会使用lxml模块中的etree库来解析HTML或XML文档,导入方式如下:
from lxml import etree
XPath基本语法
XPath(XML Path Language)是一门在XML和HTML文档中查找信息的语言,它基于XML的树状结构,使用路径表达式来选取XML文档中的节点或节点集,对于手游玩家来说,XPath就像是一把钥匙,可以帮助我们精确地定位到想要的数据。
XPath的基本语法包括节点选择器、属性选择器、谓词等,下面是一些常用的XPath表达式及其解释:
/:代表从根节点开始查找。
//:代表查找所有匹配的节点,不考虑它们在文档中的位置。
@:用于选择属性。
:匹配任何元素名。
[]:用于谓词筛选,可以包含比较运算符(如=、!=、<、>等)、逻辑运算符(如and、or、not等)和XPath函数(如last()、position()、starts-with()、contains()等)。
如果你想选取所有class属性值为"item-0"的li元素,你可以使用以下XPath表达式:
//li[@class='item-0']
如果你想选取第二个li元素,你可以使用以下XPath表达式:
//li[2]
实战案例:抓取手游官网数据
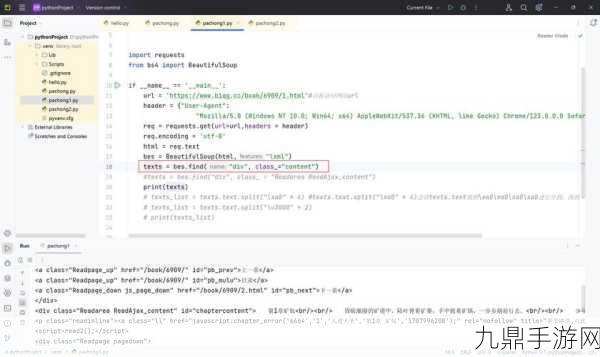
假设我们想要抓取某款手游官网上的游戏更新公告,我们需要找到公告所在的HTML元素,通过浏览器的开发者工具,我们可以发现公告被包含在一个class为"announcement"的div元素中。
我们可以使用lxml模块和XPath语法来抓取这个元素的内容,以下是一个简单的示例代码:
import requests
from lxml import etree
发送HTTP请求获取网页内容
url = 'https://example.com/game-updates' # 替换为实际的游戏官网URL
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'}
response = requests.get(url, headers=headers)
html_content = response.text
使用lxml解析HTML内容
html = etree.HTML(html_content)
使用XPath选取公告内容
announcement = html.xpath('//div[@class="announcement"]/text()')
打印公告内容
for item in announcement:
print(item.strip())在这个示例中,我们首先使用requests库发送HTTP请求获取网页内容,我们使用lxml模块的etree库将HTML内容解析为Element对象,我们使用XPath语法选取class为"announcement"的div元素的内容,并打印出来。
最新动态:与Python爬虫lxml模块相关的手游热点
1、《王者荣耀》英雄数据抓取
《王者荣耀》是一款非常受欢迎的手游,玩家们经常需要了解英雄的最新数据,比如胜率、出场率等,利用Python爬虫和lxml模块,我们可以轻松地抓取这些数据,并进行分析和比较,你可以编写一个爬虫程序,定期抓取游戏官网或第三方数据网站上的英雄数据,并生成一个排名榜单,分享给你的游戏好友。
2、《原神》角色攻略挖掘
《原神》是一款开放世界冒险游戏,玩家们需要不断探索和解锁新的角色和剧情,利用Python爬虫和lxml模块,我们可以抓取游戏社区或论坛上的角色攻略和心得分享,帮助你更快地了解每个角色的特点和玩法,你还可以将这些攻略整理成一个数据库或网站,方便其他玩家查阅和学习。
3、《和平精英》皮肤收集挑战
《和平精英》是一款射击类游戏,游戏中有很多漂亮的皮肤供玩家收集,利用Python爬虫和lxml模块,你可以抓取游戏官网或商城上的皮肤信息,包括皮肤名称、价格、图片等,你可以设计一个皮肤收集挑战活动,邀请你的游戏好友一起参与,看看谁能最快地收集到所有皮肤。
Python爬虫lxml模块安装导入和xpath基本语法的特别之处
Python爬虫lxml模块和XPath基本语法之所以在手游数据抓取领域具有特别之处,主要是因为它们的高效性和灵活性,lxml模块是基于C语言实现的,因此具有非常高的解析速度和处理能力,而XPath语法则提供了一种简洁而强大的方式来定位和提取数据。
lxml模块还支持自动补全HTML代码的功能,这对于处理不规范或缺失标签的HTML文档非常有用,这意味着即使你抓取的网页内容存在一些问题,lxml模块也能帮助你正确地解析和提取数据。
Python爬虫lxml模块和XPath基本语法是手游玩家解锁游戏数据新世界的重要工具,它们不仅可以帮助我们轻松地抓取和分析游戏数据,还可以激发我们的创造力和想象力,让我们在游戏中发现更多的乐趣和挑战。